Can AI Scale as a Business?
By Yoel Frischoff

This one should be easy, you’d think. Isn’t AI (or rather, Machine Learning) built for scale?
SCALE means different things to different people. This post specifically deals with implications for GROWTH.

Defining Scale
As investors look into Ai technology companies, they are interested in how successful they can be, and to that end, a company’s ability to scale sales and operation is critical. It is true that Ai applications rely on hoards of data to train. It is also true that Ai applications are justifiable in case there are too much data, and noisy at that, to retrieve meaningful insights. But even if your software churns terabytes of information, it does not mean your business is scalable.
In order for your business to scale, you need an accelerating number of customers, resulting in accelerating revenue.
And how would you do that? The book says: Find a large problem, with as many potential customers vying to solve it.
The Challenges of Scaling Up Ai
But is Ai, as a technology, scalable? The book says: “It depends”, so let us analyze what is at play.
When we talk about Ai (Artificial intelligence) we usually mean application of Machine Learning (ML), which Tom Mitchell defined as “the study of computer algorithms that can improve automatically through experience and by the use of data”.
Without going into technical details, ML implementations start with a training phase, during which data is processed and results are rated against known results. A simplistic example is scanning thousands of images to decide whether they depict cats or dogs, with humans assessing the results and grading the success or failure of each identification by the machine.
After a while the system, by feeding the successes and failures back, learns to discern between dogs and cats in ever increasing precision. At some point, the error rate equates or falls below human threshold, and this is usually where the training stops, or deemed “good enough”.
At this stage, production begins, which is where real data is processed to reveal who’s the dog here, and who’s the cat.
This strategy is useful when there is a large enough available data to train on, and when the data keeps coming from similar sources, while the research question remains quite similar.
But what happens if there is no training data, when that data is customer specific, or when it belongs to parties that would not share it freely?
Would you be able to train a model, then implement your findings over a large market?
Here stand the challenges for Ai solution providers: Have they found a large and reasonably homogenous market? Do they have an adequate data set to train their system on?
Is this barrier to scale surmountable?
Go To Market Dilemma: Product or Service?
Consider an Ai vendor penetrating a new market, based on their learning in previous successful implementation. Said vendor would have to train their model on available data, and only then they will be able to reach out to new customers with a viable offering.
A case in point is machine translation in particular, and language applications in general. By and large, machine translation is a high volume business in most living languages, with both large datasets to train on and large target audience and expected usage.
The result is a rich set of language applications, ever evolving to domains from Machine translation to Speech To Text, to Text To Speech, Summarization, and beyond.
Is it possible that the universal nature of language processing has a positive impact on the availability of general use language applications? After all, industry specific jargons are easily contained within a language syntax, and mastering new domains is easier when there are available data.
In contrast, we may consider machine vision problems, which tend to be fiendishly specific. It is not trivial to train a system to discern between cats and dogs, when the data fed to it for training does not contain enough of those, or when the input images diverge from certain levels.
Is it not fair to say, then, that machine vision requires more domain specific training?
Scale and Modality
Let’s analyze this topic with eye on scalability and growth, as impacted by the go-to-market modality:
Suppose you were to develop a solution to a problem - Will you cater to your customers in professional service (project) mode, building a team, employing your knowhow to deliver a working system in place? Or will you provide a tool (product) which the customers could operate and deploy themselves?
This dilemma has wide repercussions on your business model, on the fees you must charge to recuperate your costs. With professional services, you must deploy highly trained people to solve a single customer’s needs. It will invariably reflect on your cost structure, on your pricing, and as a result, on the number of prospective customers.
The professional service model also impacts your throughput in terms of customers / per period, given constraints of your team size, and while your team builds solutions for newly acquired customers, it cannot process new ones.
Compare a hypothetical Growth patterns for professional services (blue), Enterprise software (red), and SaaS (Green):
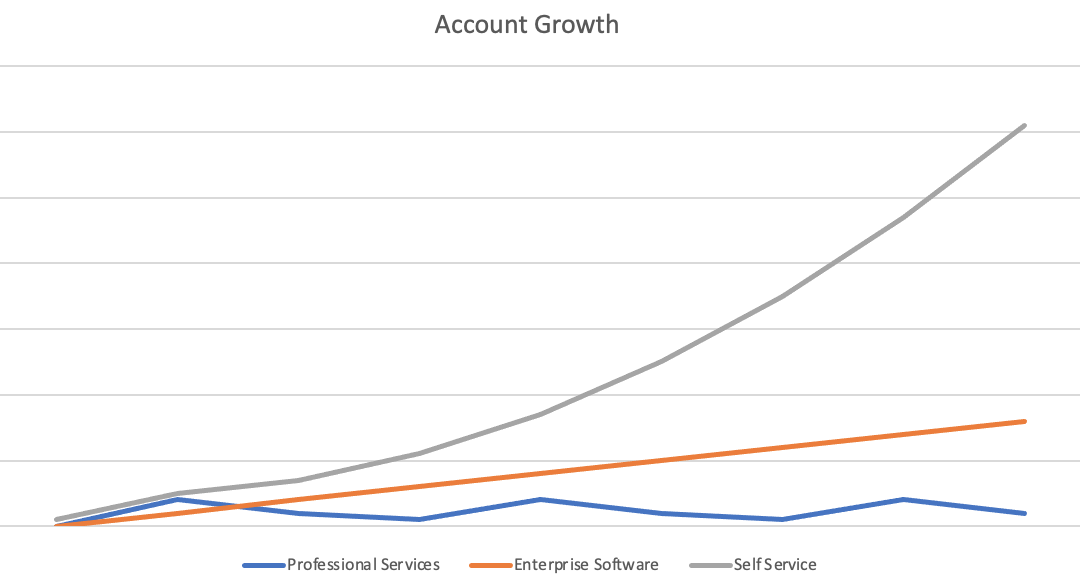
Professional Services (blue); Enterprise SW (red); SaaS (green)
Each modality has different dynamics, depending on sale cycle, integration period, and capacity constraints.
As the solution matures (on the Project➛Product axis) , its implementation becomes ubiquitous and can be relegated to customers, resulting in higher scale.
Do note, however, that at a given level of internal resources, Professional Services do not scale.
The Tragedy of the Commons and Ai’s barriers to Scale
We previously discussed the difference between general purpose problems (language applications) and specialty problems (machine vision applications). This comparison isn’t very fair though, and why?
Language, by definition, is an artificial construct, based on abstraction and generalization. True, languages have their limitations, but in terms of amenability to machine learning they offer significant advantages over vision - where a much more low-level, noisy, data flows.
Machine vision problems are here to stay, and this post concentrates on the challenges and barriers Ai vendors face when trying to solve them in a scalable way.
Consider the Process Industry. Equipment vendors provide production machines and lines necessary for manufacturers to turn raw material into products. To manufacturers, quality and yield - the percentage of acceptable products in each manufacturing batch - are key parameters determining to a great degree their gross profit. Efficient manufacturers can set lower prices, increase sales and revenues, and therefore, equipment vendors compete on the yield and quality of their own machines, to be more attractive to manufacturers.
Now, each machine and industrial process differ in parameters, in manufacturing defects, and on the methods employed to control them. This is where Ai, machine vision especially, can contribute - in replacing human quality assurance - prone to fatigue and limited in scope (for instance, machine vision can use wavelength invisible to the human eye as source data).
And here is the thing: As machine vision vendors producing inspection software need to train their system on each machine, and for each manufacturing scenario, the question emerges: Whose data are they going to employ for training, and to what end?
Would vendor A allow their data spill to over to machines produced by vendor B, eroding their competitive advantage? And would a manufacturer provide training data that would spill over to the whole industry, eroding theirs? This is the tragedy of the commons at play: Each player’s interest lie in contrast to the common good (and, on average, to their own).
The structure of the market, the competitive forces, and the maximizing interests of the players, then, set a suboptimal result, in which Ai vendors will be less incentivized to invest in this particular domain.
This deficiency has a direct impact on the potential growth of Ai vendors: If the data given to them for training remains proprietary and cannot be shared, how would they scale their solution across industries?
Scale Strategies
This problem is not unique to Machine Vision or to Ai in general. Several strategies have been devised and successfully employed in other technology sectors.
The research, formulation, and implementation of such strategies, however, are beyond the scope of this post.
Wondering how to scale your own Ai solution in a fragmented market? Come talk to us.
